Il Web Crawler Avanzato fornisce alla Conversation AI di GoHighLevel / Squadd una nuova capacità: apprendere da siti web interattivi con la stessa facilità delle pagine statiche. Raccogliendo automaticamente fino al 50% in più di contenuti presenti sulla pagina (inclusi tab, accordion e sezioni a caricamento lazy), il tuo bot può rispondere a più domande con maggiore precisione.
- Cos'è il Web Crawler Avanzato?
- Vantaggi principali del Web Crawler Avanzato
- Estrazione intelligente di contenuti dinamici
- Scoperta avanzata dei link
- Supporto universale per siti web
- Come utilizzare il Web Crawler Avanzato
- Domande frequenti
- Articoli correlati
Cos'è il Web Crawler Avanzato?
Il Web Crawler Avanzato è il motore di acquisizione dei siti web aggiornato all'interno di Bot Training. Simula le interazioni di un visitatore reale: apre accordion, clicca sui tab, scorre la pagina e rivela dati caricati dinamicamente, estraendo ogni informazione nascosta nel tuo sito. Questa conoscenza più ricca viene aggiunta al set di addestramento del bot, insieme alle opzioni di crawling già esistenti per URL esatto, dominio e percorso.
Vantaggi principali del Web Crawler Avanzato
- Estrazione testuale approfondita: Cattura dal 30 al 50% in più di contenuti sulla pagina da SPA moderne (React, Vue, Angular, Gutenberg, ecc.).
- Rilevamento contenuti nascosti: Legge accordion, tab, modal, sezioni a caricamento lazy e a scorrimento infinito.
- Parsing multi-strategia rapido: Esegue in parallelo 12+ strategie di rilevamento dei contenuti per massimizzare la velocità.
- Motore di interazione sicuro: Evita clic rischiosi come l'invio di moduli, la modifica di filtri e le azioni sul carrello.
- Estrazione parallelizzata: Riduce il tempo totale di crawling su siti grandi e complessi.
- Metriche di crawling utili: Monitora tempo, interazioni, lunghezza dei contenuti e memoria per ottimizzare e risolvere eventuali problemi.
Estrazione intelligente di contenuti dinamici
- Espande automaticamente gli accordion, naviga tra i tab, attiva il caricamento lazy e rivela i contenuti nascosti
- 2+ strategie di rilevamento intelligente (contenuto semantico, dati strutturati, metadati) eseguite in parallelo per un'estrazione fulminea
- Motore di interazione sicuro che evita azioni invasive come l'invio di moduli o la modifica di filtri
Scoperta avanzata dei link
- Crawling ricorsivo della sitemap: Scopre ed elabora in modo ricorsivo le sitemap annidate per migliorare il rilevamento degli URL su strutture di siti multi-livello.
- Supporto sitemap compressa: Supporta file sitemap compressi (ad esempio,
.xml.gze.gzip) per ridurre il consumo di banda e migliorare l'efficienza del crawling. - Guardia alla navigazione: Rileva i confini di navigazione per ridurre la deriva del crawler e mantenere la scoperta nell'ambito della knowledge base prevista.
- Rilevamento multi-sorgente: Parsing HTML + valutazione JavaScript + scoperta basata sulle interazioni
- Scopre link nascosti dietro sezioni espandibili e contenuti dinamici
- Deduplicazione intelligente con conservazione del testo descrittivo dei link
Supporto universale per siti web
- Funziona con qualsiasi tipo di sito web: HTML statico, WordPress, SPA React, app Vue, applicazioni Angular
- Crawling più veloce grazie all'estrazione parallela dei contenuti
- Osservabilità completa con metriche dettagliate (tempo di elaborazione, interazioni, lunghezza dei contenuti, utilizzo della memoria)
Come utilizzare il Web Crawler Avanzato
Passo 1: Accedi alla Knowledge Base
- Clicca su AI Agents dalla tua Location.
- Clicca sulla scheda Knowledge Base.
- Crea una nuova Knowledge Base oppure Modifica una esistente.
- Clicca sul pulsante + Aggiungi sorgente.
- Clicca su Web Crawler.

Passo 2: Seleziona il tipo di dominio e inserisci il dominio
- Sono disponibili più tipi di dominio che puoi scansionare per addestrare il tuo bot. Il tipo di dominio scelto determinerà quanti URL verranno analizzati per l'addestramento.
- URL esatto: Scansiona una pagina web specifica per utilizzarne i dati nell'addestramento. Ad esempio, inserendo https://www.gohighlevel.com/ il crawling si limita a quella precisa pagina web.
- Tutti gli URL con il percorso: Scansiona tutte le pagine all'interno di un percorso specifico. Ad esempio, inserendo https://www.gohighlevel.com/marketing vengono incluse tutte le pagine che usano quel percorso URL, come /marketing/offers o /marketing/promotions.
- Tutti gli URL nel dominio: Scansiona tutte le pagine all'interno di un dominio. Ad esempio, inserendo https://www.gohighlevel.com/promo vengono incluse tutte le pagine con il dominio radice www.gohighlevel.com.
- URL esatto: Scansiona una pagina web specifica per utilizzarne i dati nell'addestramento. Ad esempio, inserendo https://www.gohighlevel.com/ il crawling si limita a quella precisa pagina web.
- Aggiungi l'URL.
- Clicca sul pulsante Estrai dati.
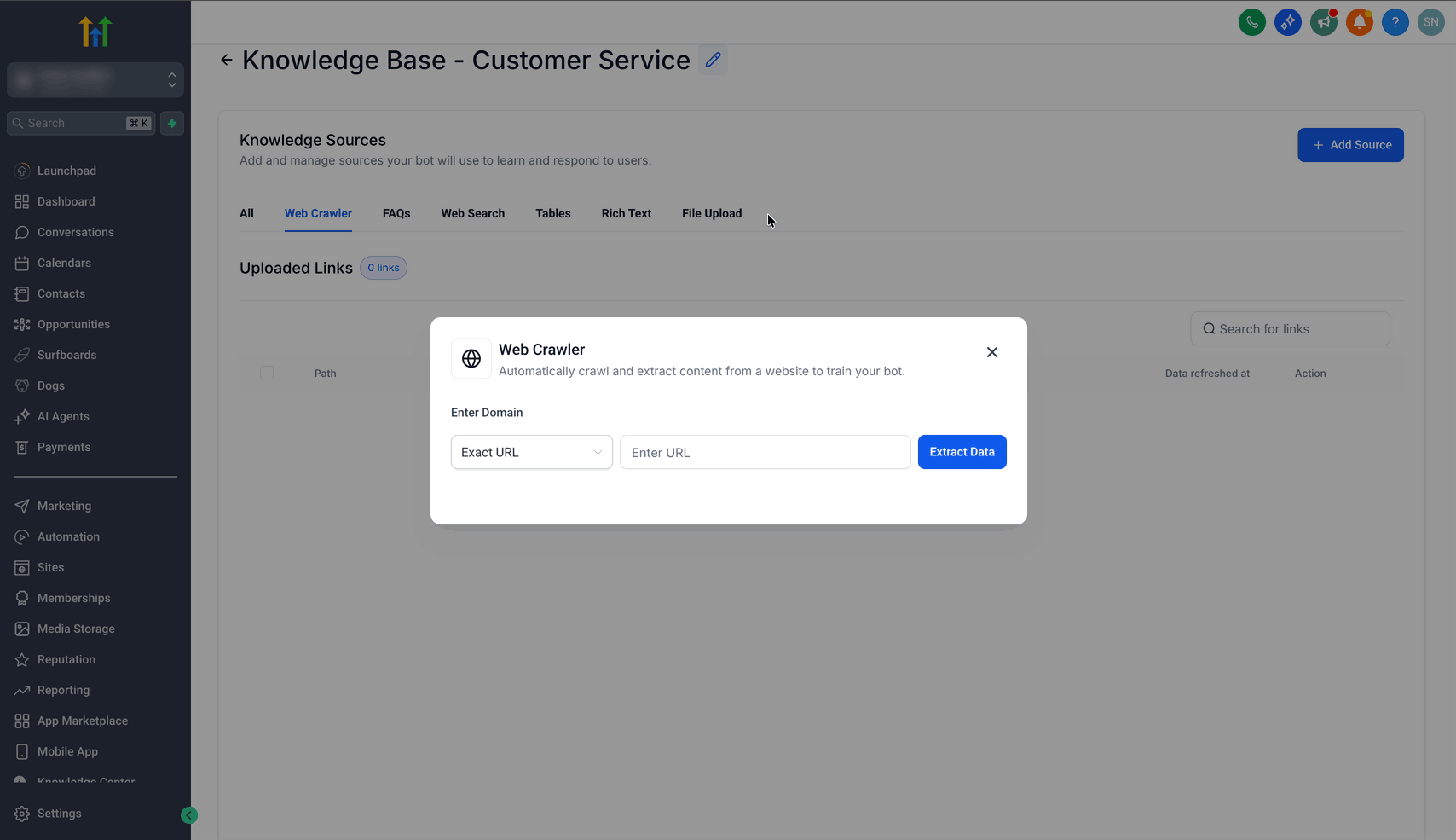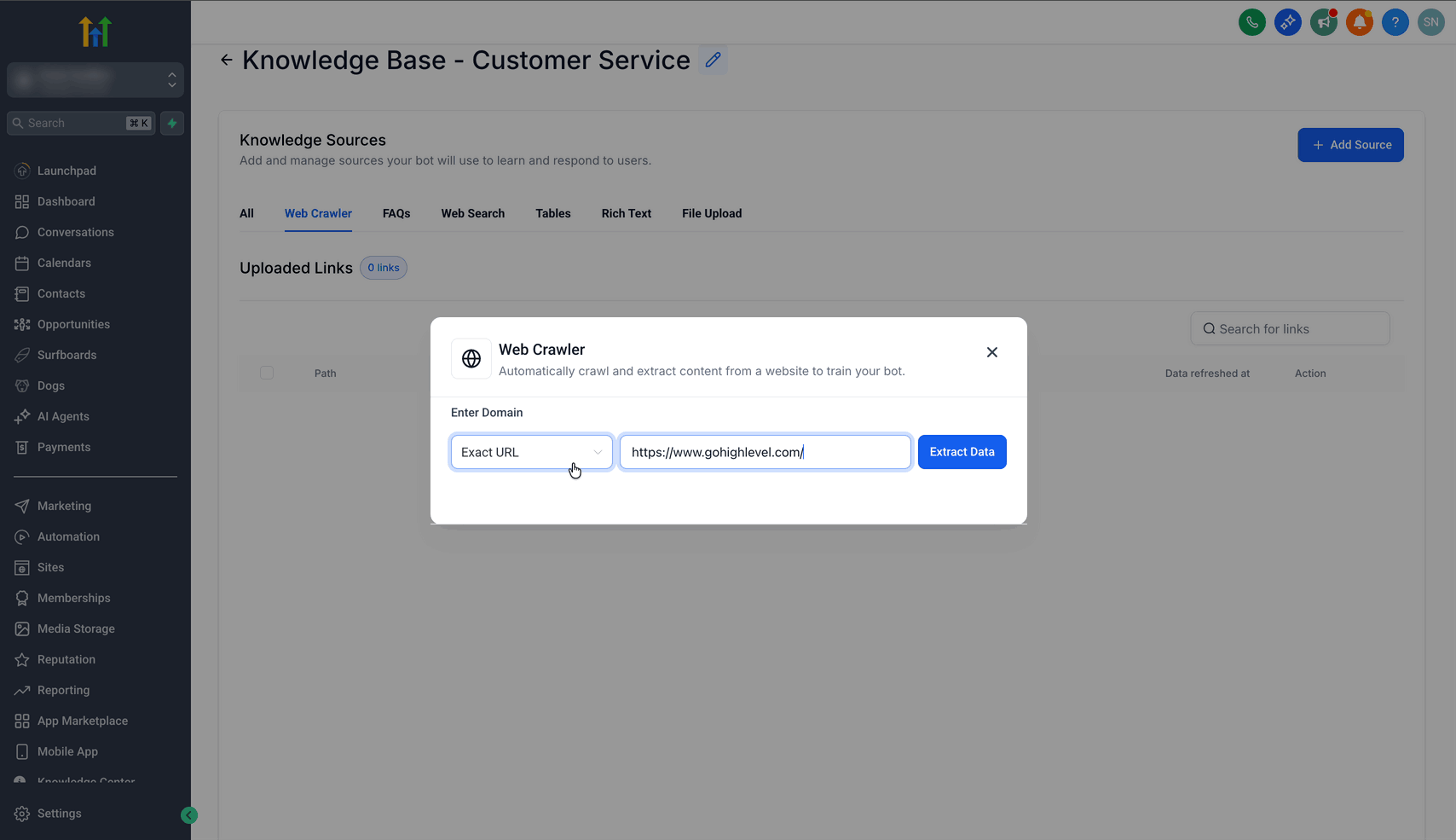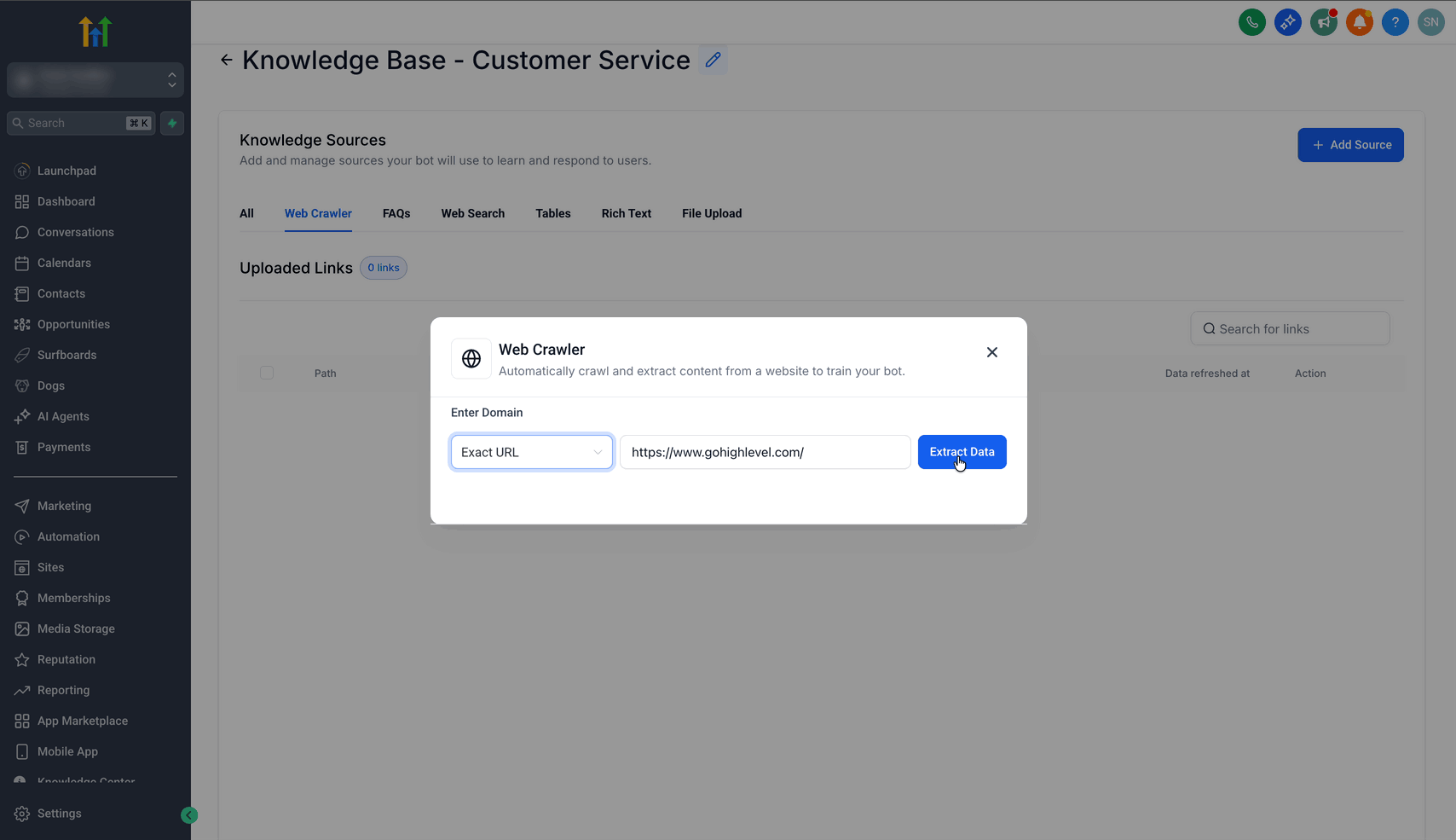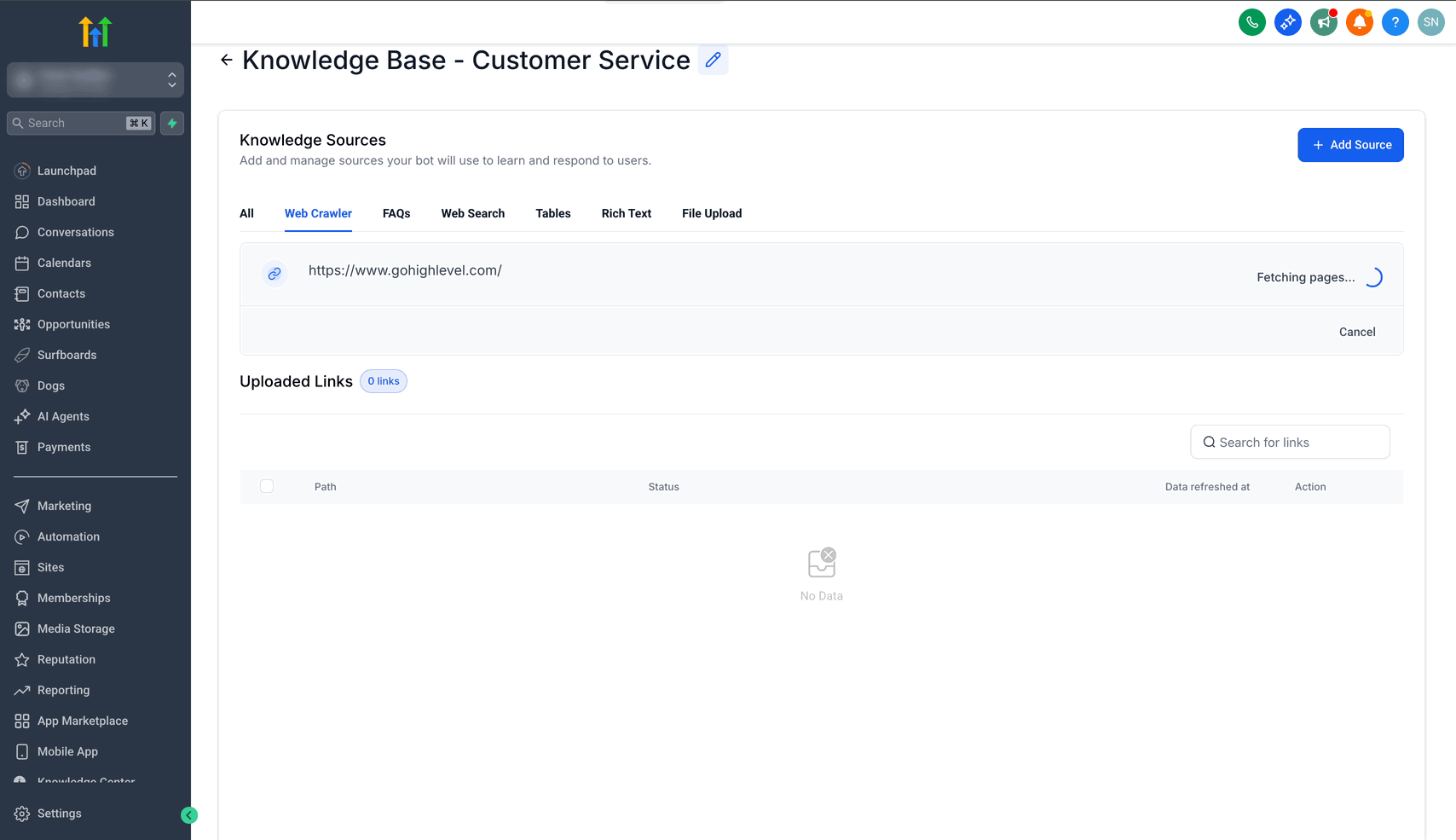
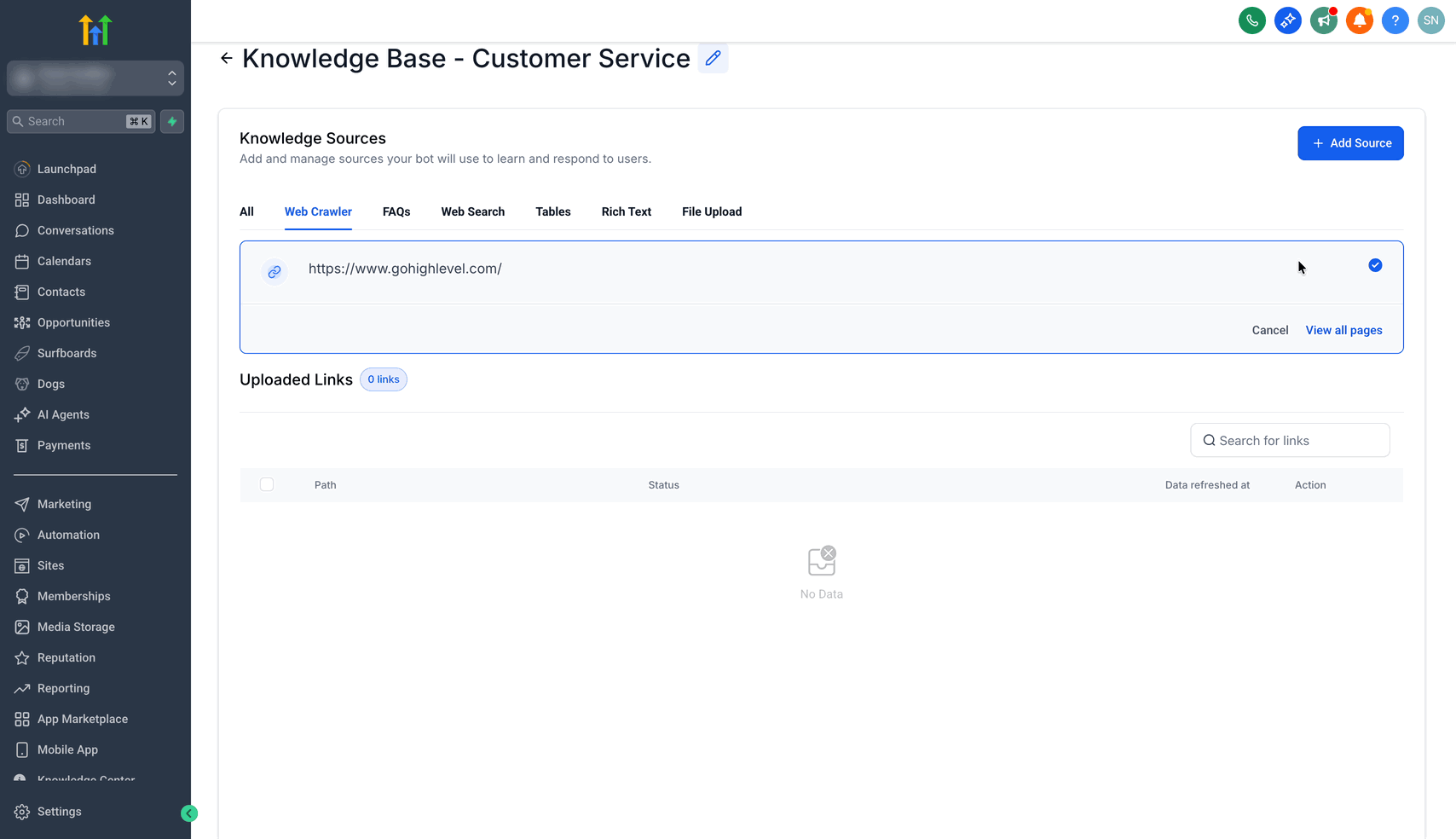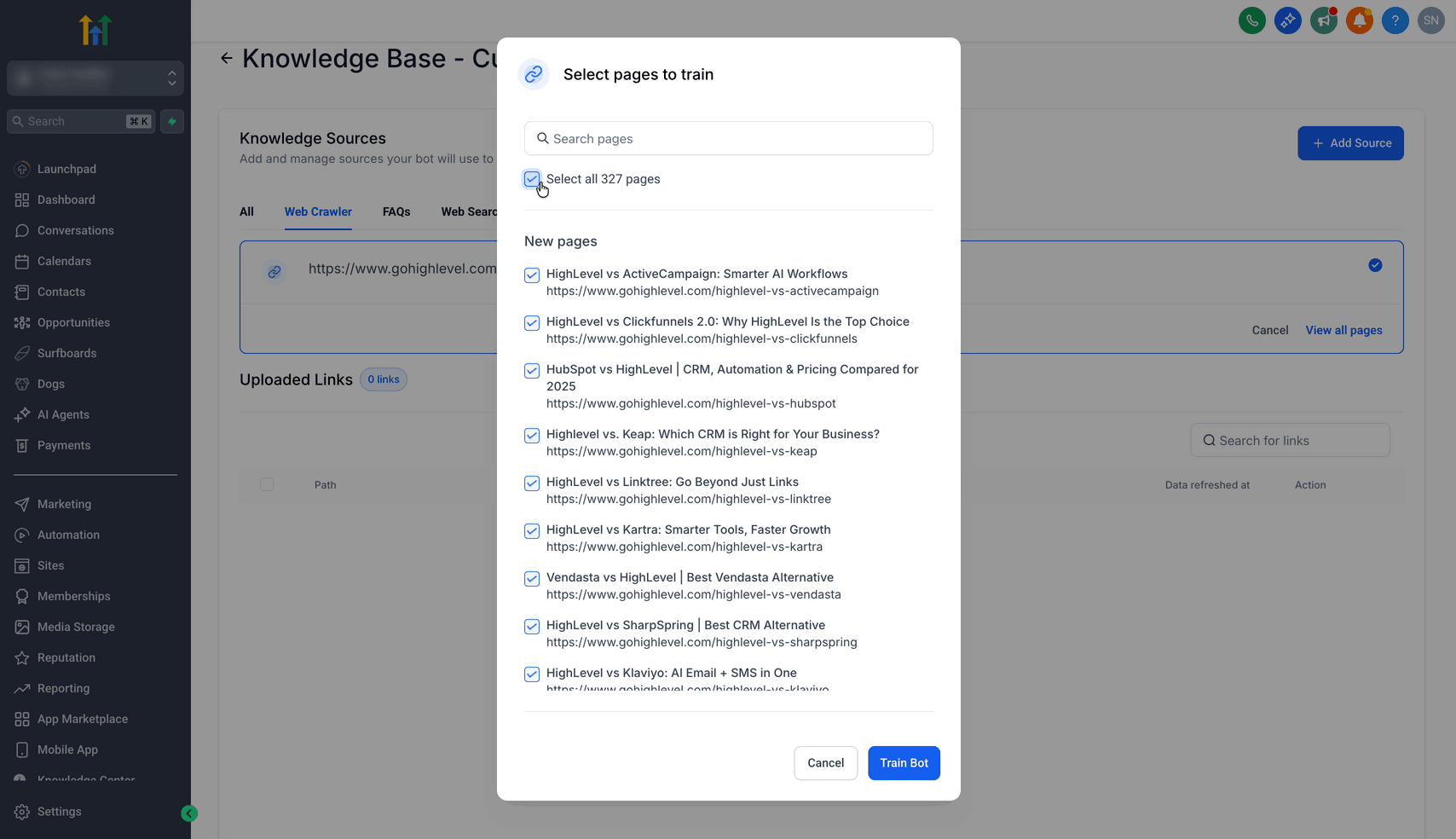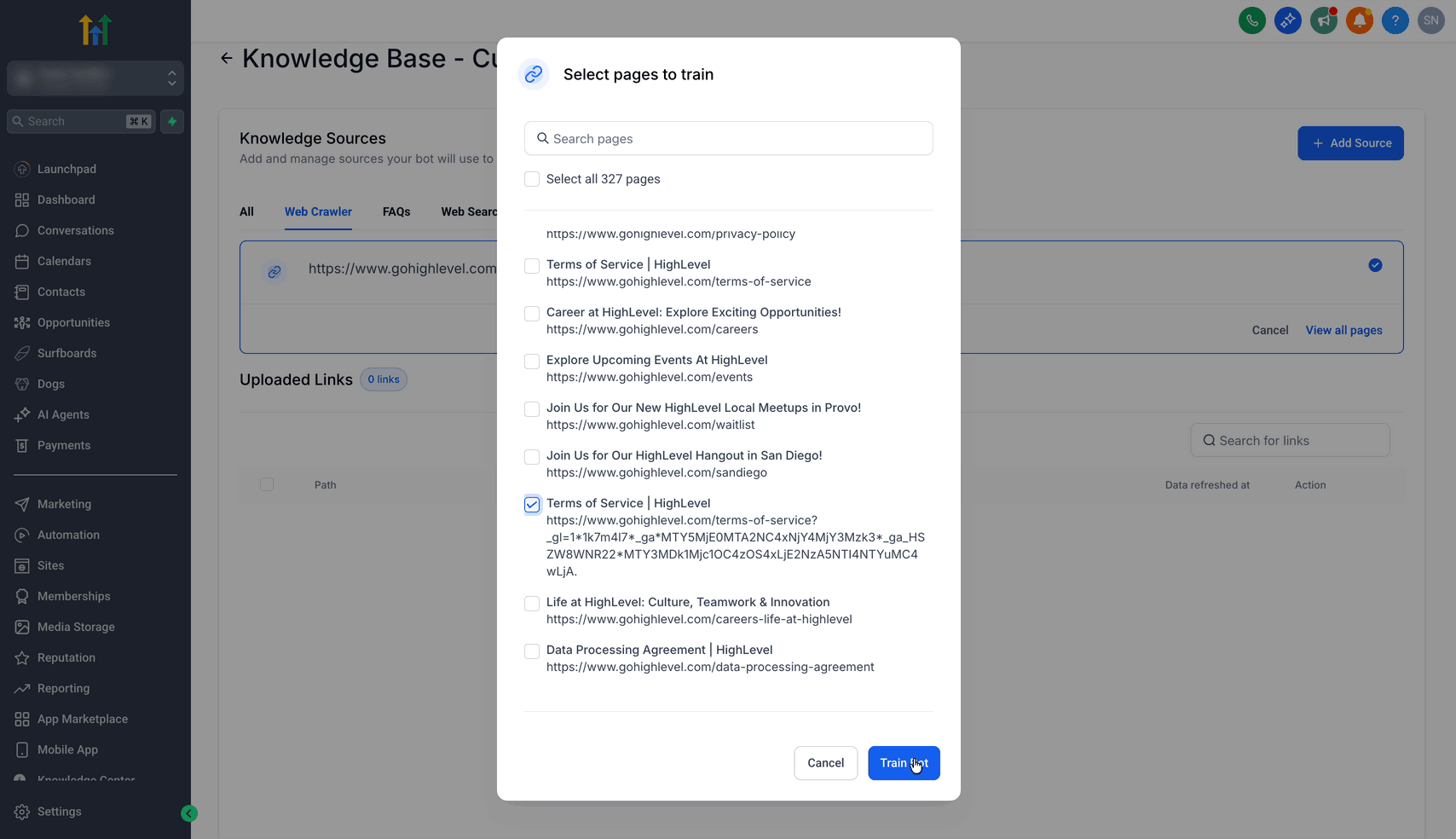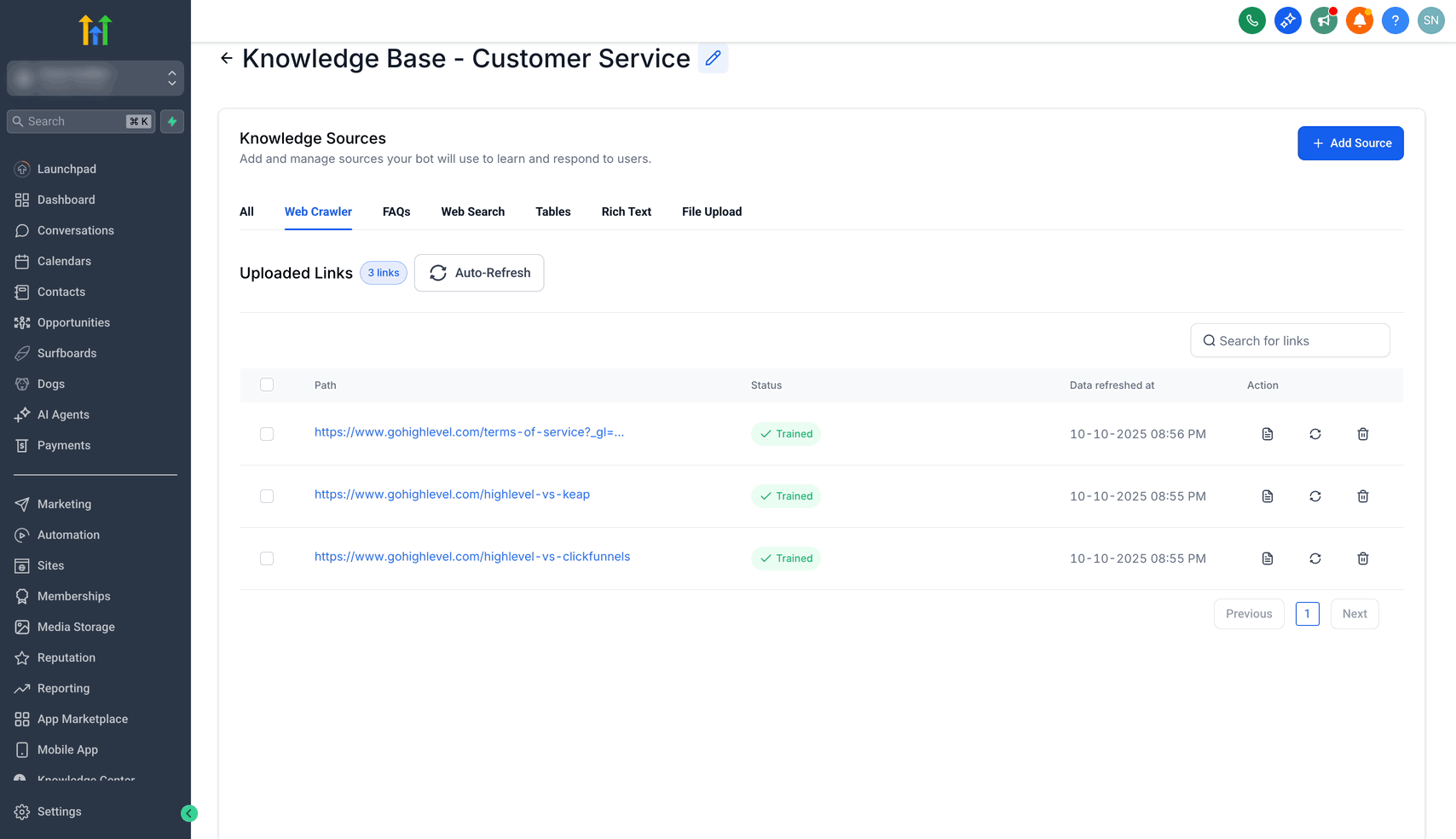
Passo 3: Seleziona gli URL scansionati
- Una volta completata la scansione degli URL, clicca sull'opzione Visualizza tutte le pagine.
- Puoi "selezionare tutti" gli URL oppure selezionare singoli URL cliccando la casella di spunta accanto all'URL che vuoi aggiungere ai dati di addestramento.
- Dopo aver effettuato la selezione, clicca sul pulsante Addestra il Bot.
Domande frequenti
D: Cosa significa "scoperta dei contenuti più intelligente"?
Il crawler acquisisce ora fino a 5,2× più contenuti dal sito web, inclusi testimonianze, funzionalità, dettagli di contatto e descrizioni dei servizi che in precedenza venivano spesso trascurati.
D: Quanto è affidabile l'addestramento con il nuovo crawler?
Il tasso di successo è migliorato dall'81,6% al 94,7% su tutti i tipi di sito — business, e-commerce e interattivi moderni — quindi le acquisizioni falliscono molto meno frequentemente.
D: Devo configurare qualcosa per estrarre le sezioni principali?
No. 6+ strategie di rilevamento in parallelo trovano automaticamente sezioni hero, testimonianze, descrizioni di prodotti, biografie del team, tabelle prezzi e informazioni di contatto.
D: Può leggere contenuti interattivi o nascosti?
Sì. Espande gli accordion, naviga tra i tab e rivela sezioni a caricamento lazy o nascoste per acquisire testimonianze complete e informazioni dettagliate sui servizi.
D: Quali dati strutturati estrae e perché è importante?
Estrae il 94% in più di dati strutturati (orari di apertura, dettagli di contatto, prezzi, servizi), fornendo alla tua AI una comprensione più ricca e precisa della tua attività.
D: Cliccherà sui pulsanti di checkout o invierà moduli?
No. Il motore di interazione sicuro ignora gli elementi dei moduli, garantendo che non avvengano invii accidentali.
D: Cosa succede se il crawler non riesce ad accedere a una sezione nascosta dietro un login?
Il motore di interazione funziona solo con contenuti pubblicamente accessibili. I dati privati o protetti da login non verranno scansionati.